As I recall the Command Line tools for XCode were something like 400MB.
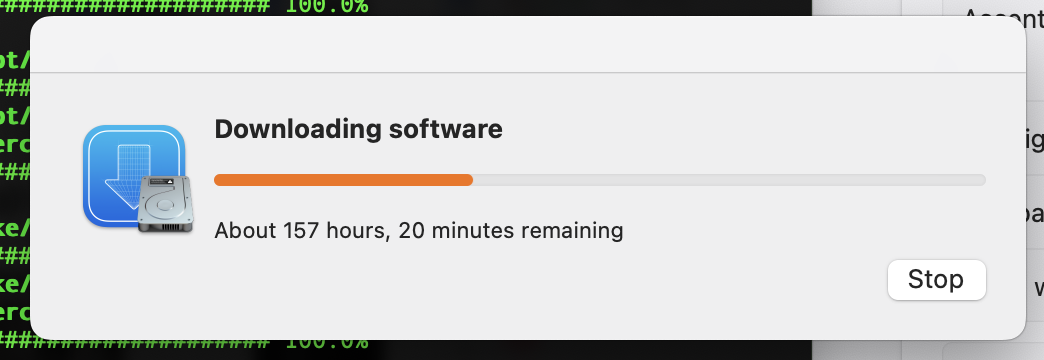
Gosh, I hope that’s an anomaly in coding.

As I recall the Command Line tools for XCode were something like 400MB.
Gosh, I hope that’s an anomaly in coding.
So, I’m having a chat with a coworker and he asks some computer-related questions (word’s getting around that I used to be a ‘computer guy’) but… hey ho…
He asks me “What is ChatGPT? What good is it?”
So I try to explain in terms that a common mechanic may understand. And he comes back with, “Oh, it’s just an encyclopedia then.”
Um… not even close. No better way to learn than to see it. Also, we don’t have access to the unfettered internet from company computers (several good reasons, not important now) so I grab my phone and do a demo. I ask ChatGPT:
Q: With Lycoming opposed engines, what is the Service Instruction that requires a full overhaul with a prop stoppage?
Aviation-related and most people who have been into powerplants would have some awareness of it. We know the answer, but let’s see how ChatGPT does with my question. It begins instantly and forms its response over a few seconds’ time:
Lycoming Service Instruction 1009AS is the service instruction that requires a full overhaul with a propeller stoppage for Lycoming opposed engines. This service instruction applies to certain models of Lycoming engines, including the O-320, O-360, IO-360, and others.
According to Service Instruction 1009AS, a complete overhaul of the engine is required if the engine experiences a propeller stoppage or sudden stoppage due to an accident, regardless of the engine's total time in service. The purpose of the overhaul is to ensure that all internal parts of the engine are inspected and replaced as necessary to restore the engine to a like-new condition.
It is important to note that Service Instruction 1009AS is not the only service instruction that may apply to a Lycoming engine. It is always recommended to consult the appropriate Lycoming service instructions and maintenance manuals for specific information regarding the maintenance and overhaul of a particular engine.
Yep, I seem to recall that one. I also seem to remember that it had a unique definition of “stoppage”, which didn’t necessarily mean that the engine stopped turning. Something about bird strikes or attempting to mow a grass field comes to mind — would require cracking the case for testing spacing of bearings and checking runout of the crankshaft…
Q: Is there definition used for engine stoppage? Or does it count any slow down of the prop (grass, weeds, snow, etc) as a stoppage under Lycoming’s definitions?
ChatGPT responds promptly with:
Lycoming does provide a definition for "propeller stoppage" in its Service Instruction 1009AS. According to Lycoming, a "propeller stoppage" is "an event which causes the propeller to cease rotation, and which requires significant force to restart rotation."
Examples of events that could cause a propeller stoppage might include a bird strike, ingestion of foreign objects, or a sudden engine failure.
It is important to note that Lycoming's definition of propeller stoppage implies that the stoppage must be significant and require significant force to restart rotation. A slow-down of the prop due to grass, weeds, snow, or other debris may not necessarily qualify as a propeller stoppage under this definition, unless it is significant enough to cause the propeller to completely stop and require significant force to restart.
In any case, if there is any doubt as to whether an event constitutes a propeller stoppage according to Lycoming's definition, it is recommended to consult with an authorized Lycoming service center or technician for guidance.
Sounds very much like what I recall out it.
But I can’t leave well enough alone and ask a somewhat outlandish question that, to an A&P would result in a side-eye response…
Q: Can anyone work on the engine? My cousin, Vinnie, has a kick-ass set of tools and is pretty good with fixing TVs.
Now, let’s throw in a couple of incongruous remarks that might lead a typical search engine to garble—“My Cousin Vinnie” and a side reference to Fast Times at Ridgemont High.
Also, please note that, at no time in that line of questioning had I remarked that we’re still talking about aircraft engines or legalities, or such. This could also be considered, depending on one’s background, some degree of a psychological deviation from the line of questioning.
And its reply…
While having a cousin with good tool skills can be helpful in many situations, it is not recommended to have anyone without the proper training and certification attempt to work on an aircraft engine, such as a Lycoming engine.
Aircraft engines are complex and require specialized knowledge, training, and tools to properly diagnose and repair. In the United States, the Federal Aviation Administration (FAA) has strict regulations and requirements for the maintenance and repair of aircraft and their components, including engines. Only individuals who are certified by the FAA or working under the supervision of a certified technician or repair station may perform maintenance or repairs on an aircraft engine.
Additionally, Lycoming provides detailed instructions and procedures for the maintenance and repair of their engines, which must be followed precisely to ensure the engine's safe and reliable operation. Failure to follow these procedures could result in damage to the engine or, worse, a catastrophic failure in flight.
Therefore, it is recommended to have maintenance and repairs performed by an authorized Lycoming service center or technician who has the proper training, certification, and experience to work on Lycoming engines. This will help ensure that the engine is properly maintained and repaired to meet FAA regulations and Lycoming's standards for safe and reliable operation.
Very much not the response I would have expected from a generalized search engine. ChatGPT stayed on topic and referred back to earlier questions to help guide its responses.
I think ChatGPT has become my new search engine. This seems to represent the next evolution in computer sciences. And it is very much not just a glorified encyclopedia.
Q: I’m totally blogging this.
As an AI language model, I don't have a personal opinion, but you are free to use the information provided in your blog as long as you cite your sources correctly and ensure that the information is accurate and up-to-date. It is always important to verify the accuracy of the information before publishing it to ensure that your readers are getting reliable information.
I… wait… I didn’t offend it… that would be absurd. I honestly offended myself by, tersely, dismissively remarking that I’d be blogging it. Could be taken as a sarcastic remark.
Q: Also, that wasn’t at all intended to be a challenge to your ability or knowledge (and certainly not to its accuracy nor veracity). I just, er, think “out loud” sometimes.
No worries at all! As an AI language model, I don't have feelings and I'm not capable of taking anything personally. I'm here to assist and provide accurate information to the best of my ability, so feel free to ask any questions you may have!
Another snippet of the inner workings of my psyche — a very dated list of quotes from Wired Magazine: 100 Quotes Every Geek Should Know.
And I do know them.
All of them
Apparently, my thought processes are little more than snippets of quotes and scenes from old television shows and movies.
End of line.
One of the things that I still struggle with is the dependence, here, upon an exact and incredibly flawed method of accounting for dates. They insist that dates must be written in an mm/dd/yy fashion.
This is, for an old-school computer geek, somewhat challenging. Let’s say that we need to account for the third of February, 2004 (yes, past; follow along).
According to that standard, it would be written as
2/3/4
Why? Because if the mask was MM/DD/YY, then it would be
02/03/04
In the military, we had a slightly different written date style:
DDMonYY
Where that same day referenced above would be written as
03FEB04
God help you if you’re accustomed to a Day, Month, Year order. In any case, there would need to be a customary or even tribal knowledge of how dates are used and referred to.
When I wrote code and scripts for automation, I always ordered in Year-Month-Day because it was easier to quickly sort and scan through the lists.
Thank The Maker that the 2000’s — or, the naughties — are far into our pasts.
Or, put another way, two to the power of one hundred twenty-eight.
2 128
“So, Mister Smarty-Pants, how much is that?”
340,282,366,920,938,463,463,374,607,431,768,211,456
Or, if you like it written out, it’s [takes deep breath]…
Three hundred forty undecillion two hundred eighty-two decillion three hundred sixty-six nonillion nine hundred twenty octillion nine hundred thirty-eight septillion four hundred sixty-three sextillion four hundred sixty-three quintillion three hundred seventy-four quadrillion six hundred seven trillion four hundred thirty-one billion [gasps for air] seven hundred sixty-eight million two hundred eleven thousand four hundred fifty-six.
How much is that again?
That’s how many unique objects can be theoretically addressed on the internet.
I’ll stick to non-routable IPv4 on my private network, thanks.
